Apakah Anda penganut aliran saham yang sama dengan saya, feelingmology. Feelingmology didefinisikan sebagai suatu kondisi dimana ketika melihat saham incaran yang sudah turun 30%, terbersit di pikiran, wah feeling-nya bakal balik ke harga awal nih, bisa profit 50%, cuancuancuan. Eh ternyata, karena satu dan lain hal, seperti kondisi makroekonomi dunia, harganya malah turun dan, dan turun, dan turun terus menerus. Sehingga Anda yang sebenarnya cuma mau trading sebentar, terpaksa menjadi long term investor bertahun-tahun dan harus melakukan average down.
Contohnya, saya punya saham UNVR yang saya koleksi terus dari harga 8000 hingga sekarang memiliki average di harga 6000. Nah berapakah jumlah lot yang harus dibeli dan total uang yang harus saya keluarkan, kalau misalkan saya mau membeli di harga sekarang hingga harga rata-rata saya menjadi 5000?
Untuk melakukan hitung-hitungan seperti itu tentunya bisa dilakukan di dalam spreadsheet. Tapi tahukah Anda kalau Anda juga dapat mendapatkan harga saham secara otomatis di dalam Excel, sehingga kita bisa dengan mudah mensimulasikan proses average down tersebut?
Langkah pertama, cukup ketik kode emiten saham tersebut di cell mana saja di dalam Excel.
Kemudian pilih tab data, dan klik tombol Stocks di pane data types
Setelah nama emitennya berubah menjadi panjang, tekan floating button di kanan atas dari cell-nya dan pilih menu Price untuk mendapatkan harga terkini dari emiten tersebut.
Sekarang kita tinggal memasukkan data saham yang kita miliki seperti jumlah lot dan harga average sekarang kemudian menuliskan formula untuk mendapatkan harga rata-rata yang baru. Dengan mengganti jumlah lot-nya, kita bisa bereksperimen untuk mendapatkan harga terbaru sesuai dengan yang diinginkan.
Coba ada sekuritas di Indonesia yang membuka API untuk melakukan jual beli sahamnya, pasti lebih asik karena semua prosesnya bisa diotomatisasi dengan menggunakan script.
Hampir semua orang di seluruh dunia yang nonton Youtube tahu apa itu VPN, karena sering sekali menjadi sponsor dari banyak video di sana (nordvpn, surfshark, etc). Wajar sih, karena memang bisnis software ini profit margin-nya besar dengan practically 0 marginal cost untuk setiap customer baru sehingga mereka bisa menghabiskan dana yang besar untuk marketing (CAC tinggi tapi CLV lebih tinggi).
Kegunaan utama yang sering dipromosikan antara lain, membuat koneksi lebih aman jika lewat wifi yang tidak dikenal (walaupun sekarang kebanyakan website sudah https), mengakses website yang diblokir (seperti reddit di Indonesia), atau membuka konten Netflix yang hanya tersedia di negara tertentu. Tapi tahukah Anda kalau ternyata vpn juga bisa digunakan untuk mendapatkan buku dengan harga yang lebih murah?
bookdepository adalah situs yang menjual buku dengan pengiriman gratis ke seluruh dunia. Ya, betul. Gratis. Dari segi inventory-nya pun cukup lengkap, semua buku yang biasa ditemui di toko semisal kinokuniya atau periplus tersedia, kerap dengan harga yang lebih murah. Hal lain yang menarik adalah adanya visualisasi setiap buku yang baru dibeli di dalam sebuah peta dunia. Dulu saya pernah ingin buat hal yang mirip di Traveloka, dimana kalau ada yang beli tiket, ada animasi pesawat terbang dari airport asal ke tujuan, tapi tidak jadi karena banyak kerjaan lain yang lebih mendesak.
Tentu tidak ada yang benar-benar gratis di dunia ini. Dalam kasus bookdepository mereka memasukkan biaya shipping ke dalam harga bukunya, sehingga harga bisa berubah apalagi situsnya diakses di bagian dunia yang berbeda (tebakan saya ada ML model di dalamnya untuk menentukan pricing ini). Contoh, setelah menonton Dune, saya mau baca bukunya. Kalau saya buka dengan IP Indonesia maka harganya sekitar 300 ribu, namun dengan menggunakan vpn dan mengeset lokasi ke Singapura, harganya bisa 10% lebih murah.
Contoh buku lain yang lumayan diskonnya. Sebenarnya saya set lokasinya di Swedia, tapi terdeteksi sebagai Jerman. Mungkin ML model-nya belum di-update pakai data training baru.
Tapi tidak semuanya jadi lebih murah di luar Indonesia, ini contohnya. Jadi kalau mau paling murah memang cari area untuk semua buku yang ingin dibeli. Mungkin bisa dibuat programnya untuk otomatisasi itu semua?
Satu tips tambahan lagi, kalau misalkan lokasinya dideteksi di EU, maka akan ada tambahan VAT di harga yang ditampilkan, tapi kalau sudah masuk ke halaman checkout dan lokasi pengantaran diganti ke Indonesia, harga akhir akan dikurangi pajak sehingga lebih murah lagi.
Untuk pengiriman, dulu sebelum pandemic, 3-4 minggu biasanya sudah sampai. Tapi setelah pandemic jadi 1 hingga 2 bulan. Buku impor juga tidak terkena bea masuk, walaupun sebenarnya hanya untuk buku pelajaran saja. Tapi berdasarkan pengalaman saya memesan beberapa kali, cuma satu kali saya ditagih, dan sisanya gratis walaupun tipe bukunya novel.
Doraemon petualangan adalah seri cerita doraemon dimana di dalam 1 buku komik hanya ada 1 cerita panjang. Cerita-cerita ini kemudian biasanya dijadikan film yang pernah beberapa kali saya nonton di RCTI zaman dahulu kala ketika libur panjang sekolah. Sepanjang karirnya, Fujiko F Fujio telah menulis sebanyak 17 buku (+7 buku yang dikarang asistennya setelah beliau wafat). Di post kali ini saya akan me-ranking 17 buku berdasarkan kriteria seperti plot, karakter, dsb.
Ranking 17: vol 17 – Nobita di Dunia Mainan
Sebagai buku terakhir, bisa dibilang ini juga yang terlemah, walaupun tentunya tetap menghibur dan dapat dinikmati oleh seluruh anggota keluarga. Beberapa konsep di dalam ceritanya sudah pernah dieksplor sebelumnya (seperti masalah lingkungan dan sebagainya) di cerita-cerita lain dengan lebih apik. Musuh atau antagonis dalam cerita juga tidak terasa berbahaya, serta semua karakter utama tidak ada yang melakukan hal yang istimewa. Secara keseluruhan, cerita menjadi tidak terlalu berkesan.
Ranking 16: vol 6 – Nobita dalam Perang Ruang Angkasa
Singkat cerita, Doraemon membantu kudeta di planet lain (apakah dia aslinya agen CIA?). Sebagai penganut politik bebas aktif, saya kurang setuju dengan tindakan Doraemon yang mendestabilisasi suatu pemerintahan yang sah hanya karena berteman selama beberapa hari dengan eks presiden yang terguling. Selain itu pertaruhannya juga kecil, mengingat ukuran penduduk planetnya yang kecil, sehingga tidak pernah ada perasaan bahwa Nobita dan kawan-kawan berada dalam bahaya. Yang agak berbeda adalah, jarang-jarang Suneo lumayan mendapat highlight, walaupun tidak terlalu membekas karena efeknya ke cerita secara keseluruhan tidak besar.
Ranking 15: vol 7 – Nobita di Planet Binatang
Planet baru, masalah baru. Dengan tema lingkungan, Nobita dan kawan-kawan kali ini berteman dengan para hewan yang sudah berevolusi sehingga memiliki tingkat intelegensi seperti manusia, dan harus melawan manusia jahat yang akan mengambil alih planet mereka. Overall, cerita kurang menggigit karena kejadian di planet lain, sehingga Nobi dkk bisa saja pulang ke Bumi tanpa ada konsekuensi apa2. Di akhir cerita juga mereka harus ditolong oleh pihak ketiga yang entah datang dari mana. Highlight-nya mungkin ketika Nobita memakai alat untuk menjadi beruntung selama beberapa jam, yang menginspirasi bagian cerita Harry Potter menggunakan ramuan felix felicis di buku keenam berpuluh-puluh tahun kemudian.
Ranking 14: vol 1 – Petualangan Nobita dengan Dinosaurus
Sebagai cerita panjang pertama, yang dimulai dulu sebelumnya dari cerita pendek di buku2 sebelumnya, cerita ini lumayan sebagai pembuka untuk mencicipi apa saja yang bakal dihadapi Nobita dan kawan-kawan di kisah-kisah selanjutnya. Pertaruhannya nyata, apakah mereka bisa kembali ke waktu mereka dengan selamat, atau harus hidup selamanya di zaman dinosaurus. Sayangnya sebagai cerita pertama, beberapa bagian terasa kurang dipoles, seperti karakterisasi dan penjahat yang one dimensional.
Ranking 13: vol 2 – Petualangan Nobita di Luar Angkasa
Nobita dan kawan-kawan kembali ke luar angkasa, kali ini untuk melawan korporasi mega besar ala Amazon abad 22 yang mengeksploitasi sumber daya alam tanpa mempedulikan kesejahteraan penduduk planetnya. Seperti cerita di planet luar angkasa lainnya, yang ini juga sebenarnya kurang greget. Yang membedakan mungkin adalah, Nobita jadi terlihat keren dengan angle pahlawan super, apalagi ketika duel satu lawan satu di akhir.
Ranking 12: vol 8 – Nobita dan ksatria dinosaurus
Kembali dengan tema dinosaurus, tapi sekarang dengan twist melalui perjalanan waktu. Dunia bawah tanahnya juga sebenarnya sangat imajinatif dengan teknologinya yang unik, tapi mungkin konfliknya yang kurang membekas karena tidak ada antagonis asli di dalam ceritanya.
Ranking 11: vol 15 – Catatan harian Nobita
Tak puas hanya membuat tempat persembunyian di bawah tanah di cerita vol 8, Kali ini Nobita membuat alam semesta dari awal terus di speedrun sampai akhir zaman revolusi industri cuma untuk tugas pekerjaan rumah musim panas. Wow, what a dedication. Overall, ini lebih terlihat seperti kronologi dari cerita-cerita pendek dari masa ke masa. Sayangnya, kembali tidak ada peran antagonis di sini, dan resolusi konflik di akhir terasa terlalu cepat.
Ranking 10: vol 12 – Nobita dan kerajaan awan
Kali ini Nobita membuat dunianya sendiri di atas langit, tepatnya di awan. Adakah tempat di bumi ini yang belum terjamah oleh tangan jahil mereka? Tema lingkungan kembali diangkat sebagai pesan moral untuk cerita ini. Penjahat di cerita ini seharusnya tidak terlalu berbahaya. Resolusi konfliknya juga ditentukan oleh pihak ketiga, walaupun Doraemon tetap harus melakukan pengorbanan untuk mencapai hasil tersebut. Ini juga cerita yang mempunyai paling banyak cameo dari buku cerita pendek.
Ranking 9: vol 13 – Nobita dan labirin timah
Kembali menggulingkan pemerintahan yang berdaulat di planet lain, tetapi kali ini bukan hanya masalah politik, tapi juga ideologi. Selain itu, Nobita dkk juga memiliki alasan personal, yaitu untuk menyelamatkan Doraemon. Giant dan Suneo juga memiliki peran yang tidak kalah penting kali ini. Selain itu setup di awalnya juga menarik dengan angle liburan dan adanya cekcok antara Nobita dan Doraemon, walaupun agak dipaksa, tapi payoff-nya di akhir lumayan berasa.
Ranking 8: vol 16 – Nobita dan Kereta Api Ekspres
Cerita terbaik dengan latar belakang luar angkasa, dimana dimulai dengan awal santai untuk liburan, tapi kemudian berkembang menjadi pertaruhan untuk nasib satu galaksi!? Selain itu, volume ini bisa dibilang sebagai puncak dari karakter Nobita, dimana dia berkontribusi secara aktif sepanjang cerita bahkan berhasil menang melawan boss terakhir, dengan tidak hanya mengandalkan skill-nya, tapi juga kecerdikan, yang tidak pernah ditunjukkan di cerita-cerita sebelumnya.
Ranking 7: vol 3 – Nobita dalam Dunia Misteri
Volume ini sangat kental dengan aroma petualangan dari awal hingga akhir. Backdrop-nya sempurna, Afrika di daerah yang masih liar dan tak tersentuh, tanpa bantuan dari alat-alat esensial Doraemon.
Sayangnya saya kurang merasa perubahan tema yang terjadi di bagian kedua cerita berjalan mulus. Terutama karena secara teknologi harusnya kerajaan anjing masih berada di era Romawi kuno/modern, sehingga seharusnya kalah dengan persenjataan modern dari Japan self-defense force yang di-backup oleh Amerika.
Selain itu, ini adalah penampilan perdana Dekisugi di buku petualangan (btw, buat yg belum tahu, nama dekisugi itu pelesetan, deki dari dekiru alias bisa dan sugi artinya terlalu, jadi kurang lebih artinya imba atau terlalu jago segalanya). Kenapa Dekisugi tidak diajak? karena terlalu OP sepertinya, nanti semua masalah selesai cuma dalam satu panel.
Ranking 6: vol 11 – Nobita dalam Malam Dorabian
Kali ini personal, Nobita dan kawan-kawan harus menyelamatkan Shizuka. Setting-nya abad pertengahan di timur tengah. Pertaruhannya juga nyata karena Doraemon kehilangan akses ke alat-alatnya di hampir setengah cerita. Dan di akhir, Sinbad sebagai karakter tambahan juga berhasil menebus karakternya dengan baik.
Ranking 5: vol 4 – Petualangan Nobita di Dasar Laut
Dimulai dari awal cerita yang sangat comfy dengan tema piknik di bawah laut, kemudian berkembang menjadi misteri dan berakhir dengan perjuangan yang membawa nasih seluruh muka Bumi. Shizuka dan karakter tambahan Buggy menjadi highlight dari cerita kali ini. Yang mungkin menjadi sedikit kurang adalah, ancaman terhadap dunianya yang kurang dibangun sehingga reperkusinya belum menempel dengan kuat kepada para pembaca.
Ranking 4: vol 9 – Asal Usul Negeri Jepang
Dari segi base building, ini menurut saya yang terbaik, tiap karakter mendapat peran tersendiri untuk membuat negara sendiri. Selain itu, penjahatnya juga cukup memberi perlawanan yang ketat menghadapi Doraemon dan semua peralatannya.
Ranking 3: vol 14 – Doraemon dan Tiga Prajurit Impian
Dengan setting dunia mimpi, yang berarti sebenarnya apapun bisa terjadi, ceritanya sebenarnya relatif standar, klasik dunia medieval antara kekuatan baik dan jahat. Yang membuat saya suka cerita ini, karena terasa sangat personal antara Nobita dan Shizuka, dimana keduanya saling tumbuh sepanjang cerita, tanpa mengetahui identitas mereka yang sebenarnya di akhir.
Ranking 2: vol 5 – Petualangan Nobita dalam Dunia Setan
Kali ini lawannya jelas, para setan dan iblis yang datang dari luar angkasa, dengan Bumi sebagai taruhannya. Setting-nya di dunia sihir juga sangat menarik, berpuluh2 tahun lebih awal dari Harry Potter. Selain itu ada bagian misteri di cerita di awal yang ketika saya baca sewaktu kecil bisa membuat bulu kuduk berdiri merinding.
Seluruh personel memiliki sumbangsih, bahkan topi Doraemon, ketika harus menaklukkan planet iblis. Singkatnya, cerita ini punya segalanya, dan mungkin bisa jadi cerita yang paling bagus, kalau tidak oleh karena cerita nomor 1 berikut.
Ranking 1: vol 7 – Nobita dan Pasukan Robot
Dan cerita favorit saya adalah ketika Nobita dan kawan-kawan melawan pasukan kerajaan robot yang berniat menginvasi Bumi. Taruhannya jelas dan besar, nasih seluruh planet Bumi dan masyarakat di dalamnya ada di tangan mereka berlima. Hebatnya semuanya mereka lakukan sendirian tanpa ada bantuan pihak manapun.
Ceritanya juga mengalir dengan jelas, dimulai dari fase misteri di awal apa yang sebenarnya terjadi, dunia cermin yang memiliki mekanik yang sangat menarik, perasaan kalem sebelum perang, pertempuran awal yang epik, hingga momen penuh keputusasaan yang berujung dengan kemenangan.
Dari segi karakterisasi, Shizuka kembali memegang peran penting untuk menyelesaikan permasalahan. Riruru sebagai karakter tambahan adalah yang paling berkesan dibanding semua karakter di cerita lain, karena dalam waktu yang singkat bisa ter-develop dengan baik.
Singkat cerita, ini adalah cerita Doraemon terbaik.
Bagaimana menurut Anda? Apakah setuju? Cerita mana yang menjadi favorit nomor satu Anda? Silakan post dan ramaikan di kolom komentar!
Bakso sebenarnya punya cabang di mana-mana, seperti fungi setelah fase sporogenesis. Kebetulan saya makan yang di Kuningan, jadi sepertinya mungkin data scientist Tokopedia yang sering makan di sana.
Porsinya besar, dimana bakso, rusuk, serta mie-nya tumpah ruah menjadi satu dalam kontainer yang sama. Kuahnya sangat kental, seakan daging yang menempel dari rusuknya lah yang mencair setelah terlalu lama direndam. Rasanya sangat gurih, umaminya mengalir deras ke dalam tiap pori2 sel indra pengecap di lidah, tapi sayang agak terlalu berat untuk selera saya.
3. Bakso Rusuk Samanhudi
Kalau bakso ini letaknya di daerah Thamrin dekat Tanah Abang. Kata salah satu sumber saya yang dapat dipercaya, lokasinya dekat dengan kantor blibli, tapi kurang tahu apa data scientist sana suka bakso. Kelebihan bakso ini di banding bakso2 lainnya adalah konon katanya buka 24 jam (belum pernah dibuktikan secara pribadi). Cocok untuk orang insomnia atau yang lagi begadang mengejar deadline target OKR Q4.
Highlight-nya sama dengan bakso samrat, yaitu rusuknya yang besar. Bedanya, rusuknya dipisah ke dalam mangkok berbeda, yang memiliki kuah dengan racikan dan rasa yang berbeda. Daging pada rusuknya sangat empuk, hingga terasa seperti hampir meleleh di mulut seolah sudah diolah hingga mencapai titik leburnya. Tingkat kepekatannya saya bilang lebih rendah dibanding samrat, sehingga lebih cocok untuk lidah saya.
2. Bakso Akiaw 99
Bakso ini sayangnya letaknya paling jauh dari semua kantor teknologi di Jakarta, di Mangga Besar, jadi mungkin data scientist jakarta smart city yang suka beli?
Berbeda aliran dengan 2 bakso sebelumnya, yang mengandalkan intensitas rasa daging pada kuah untuk meng-uppercut indra perasa jiwa-jiwa yang memakannya, kuah bakso akiaw ini terasa sangat ringan, seakan2 bisa dimakan bermangkok-mangkok tanpa merasa jenuh. Daging sapinya terasa halus dan manis. Mie dan bakso serta kuahnya dipisah, jadi kita bisa mendesain sendiri porsi yang di-personalize berdasarkan kemampuan menandaskan isi mangkok dari masing-masing individu.
1. Bakso Mas Kumis
Terletak di daerah Slipi, cuma 10 menit lebih berjalan dari kantor Traveloka, menjadikannya favorit untuk para data scientist di sana untuk dijadikan santap siang dan malam (setidaknya dulu, circa 2018).
Kuahnya tak kalah gurih, namun tidak membuat mulut terasa eneg setelah melahapnya, sehingga sering kali orang memesan lebih dari satu mangkok setiap datang. Daging sapinya terasa sangat segar, seolah baru saja disembelih, namun tetap padat dan memberikan konsistensi yang menyenangkan ketika dikunyah.
Di sini lebih sederhana karena hanya ada satu menu bakso yang disajikan (pakai mie, pakai nasi, atau baksonya saja) sehingga bisa mengurangi cognitive load dissonance karena choice paralysis. Harganya pun paling murah jika dibandingkan ketiga tempat di atas.
Menyegerakan untuk keluar agar orang di point 1 tidak menunggu terlalu lama.
Menjadikan diri sebagai sukarelawan untuk operator lift jika berada paling dekat dengan papan tombol lift. Tanggung jawab meliputi menahan tombol buka ketika hendak ada yang masuk dan keluar, dan menekan tombol tutup setelahnya.
Berterima kasih kepada orang di point 3 ketika hendak masuk atau keluar.
Satu ciri dari sebuah organisasi yang mengaku data-driven adalah menggunakan eksperimen (atau bahasa millenialnya, a/b test) untuk membuktikan hipotesis dan mengambil keputusan. Bahkan saya berani bilang kalau kontribusi paling impactful dari seorang data scientist di dalam sebuah organisasi adalah mempopulerkan penggunaan AB test untuk membantu pengambilan keputusan di dalam dunia yang penuh dengan ketidakpastian.
Agar tidak hanya menjadi sekedar lip service belaka, perusahaan harus berani komitmen untuk invest dari sisi bisnis dan engineering, bukan hanya tim data saja. Dari sini bisnis, melakukan eksperimen selalu mengundang risiko. Bagaimana kalau versi terbaru jauh lebih buruk, sehingga user pergi meninggalkan platform-nya? Bagaimana kalau ada user yang protes karena mendapat versi atau harga yang berbeda? dan sebagainya, dan sebagainya.
Dari sisi engineering, butuh usaha untuk mendesain arsitektur dan memprogram sistem agar a/b test dapat dibuat dalam jumlah banyak dengan mudah, dimonitor, dan dievaluasi dengan cepat dan akurat. Hal ini terkadang kalah prioritas dibanding proses lain seperti bugfixing dan pengembangan fitur dari produk itu sendiri.
Microsoft sudah melakukan ribuan, sudah berapa test yang Anda jalankan? Saya minum dua
Pada post kali ini saya ingin membagi sedikit pengalaman saya dalam menjalankan beberapa eksperimen.
Bijak dalam memilih (metode)
Di statistik, ada dua pendekatan yang kerap menimbulkan konflik berkepanjangan, frequentist (null hypothesis significant test) dan bayesian. Lantas, baiknya gunakan yang mana?
Kalau menurut saya, kedua metode sama validnya untuk digunakan (tentunya dengan kelebihan dan kekurangan masing-masing), maka asas yang dipakai adalah seperti di dunia design, pilih salah satu dan konsisten dengan pilihannya. Konsisten di sini berarti kita menginterpretasi hasil eksperimen sesuai definisi dari metode yang kita pakai, tidak tercampur-campur. Seperti menggunakan definisi p-value yang tepat, atau mengerti bahwa credible interval memiliki interpretasi yang berbeda dibanding confidence interval.
hati-hati, jangan sampai terjadi civil war di kantor (based on true story)
2. Adil dalam berbagi
Bagi treatment berdasarkan user. Ini artinya gunakan cookie_id, jangan session_id (kalau bisa malah sebaiknya user_id, sehingga satu user konsisten mendapat versi yang sama di semua perangkat yang ia gunakan. Salah satu alasannya adalah untuk mengurangi kebocoran dan menaikkan false positive rate, dan agar user tidak bingung karena mendapat treatment yang berubah-ubah.
Grab sepertinya a/b test dibagi pakai session_id, karena saya tiap buka aplikasi bisa dapat interface yang berbeda-beda
Kalau sudah dibagi per user, maka sebaiknya metrics yang dipakai untuk mengukur performa antar berbagai versi juga user level metrics, seperti CTR/user, revenue/user, dan sebagainya. Hal ini juga dimaksudkan untuk menghindari naiknya false positive karena ada kemungkinan untuk tiap-tiap observasi berkorelasi satu dengan yang lain.
3. Harus berapa lama ku menunggu
Dengan menggunakan power analysis yang sesuai dengan test yang mau kita lakukan, kita bisa mengetahui jumlah sampel yang harus dikumpulkan agar hasilnya bisa statistically significant. Dari situ, dengan juga mengetahui rata-rata jumlah user yang bisa didapat perharinya, kita bisa mendapatkan butuh berapa hari untuk menjalankan eksperimennya secara keseluruhan. Lebih baik lagi kalau misalkan unitnya dijadikan dalam minggu, untuk menghindari jika ternyata ada efek weekly seasonality dari user behaviour-nya.
4. Jangan takut untuk salah
Technology/internet company memiliki kelebihan dalam melakukan eksperimen, jika dibandingkan institusi lain, seperti kampus atau rumah sakit, yaitu dalam kemudahan untuk mendapatkan test participant. Karena jika hasil eksperimennya negatif
5. Ujian bukanlah segalanya
Terakhir, janganlah berputus asa jikalau belum bisa melakukan a/b test secara baik dan benar. Ada situasi yang memang sulit sekali untuk dilakukan a/b test, misalkan menghitung efek iklan di televisi terhadap penjualan produk kita. Ada teknik yang bisa dipakai sebagai alternatif, misalkan CausalImpact.
Selain itu, tidak semua hal juga harus di-ab test kan. Gunakan akal sehat untuk memilah mana hal yang perlu dan mana yang tidak. Bahkan jika kita tidak terlalu peduli dari causal relation dan hanya mementingkan optimisasi saja, teknik seperti bandit optimization bisa saja dipilih.
Pada post kali ini, saya ingin mempopulerkan metrics yang menurut saya masih sangat underrated, terutama ketika kita bermain dengan dataset yang distribusi jumlah data antar kelasnya berbeda jauh alias imbalanced. Perkenalkan bintang utama tulisan kita kali ini, average precision!
Loh, memang apa salahnya kalau kita menghitung performa model machine learning kita untuk problem tersebut hanya dengan menggunakan akurasi saja?
Misalkan kita punya data dengan jumlah 10000. Namun hanya 40 data yang mempunyai label positif, sedangkan 9960 sisanya adalah kelas negatif. Dengan komposisi data seperti ini, kita bisa mendapat akurasi lebih dari 99% hanya dengan melakukan prediksi kelas negatif semua, seperti gambar di bawah.
Inspired by xkcd random number generator
Tentunya angka 99% tersebut tidak fair, dan model yang menghasilkan angka tersebut juga tidak berguna, karena kita lebih tertarik terhadap kemampuan model kita untuk memprediksi kelas yang positif. (Untuk tips/trik dalam menghadapi tipe problem seperti ini, bisa dilihat di post sebelumnya).
Oleh karena itu, kita membutuhkan metrics yang bisa lebih merepresentasikan performa model kita. Metrics pertama yang bisa kita pakai adalah precision dan recall. Precision menghitung berapa banyak jumlah data yang benar2 positif dari semua data yang kita prediksi sebagai positif, atau dengan kata lain true positive / (true positive + false positive). Recall menghitung berapa banyak data positif yang diprediksi sebagai positif, atau dalam rumus true positive / (true positive + false negative).
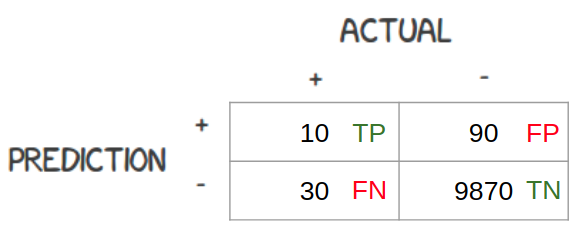
Kedua hal ini mungkin akan lebih jelas kalau melihat contoh tabel confusion matrix berikut:
Precision untuk kelas positif di atas adalah 10 / (10+90) atau 0.1 sedangkan recall-nya adalah 10 / (10+30) atau 0.25. Angka yang mungkin terlihat jauh lebih buruk dari angka 99 persen di atas, tapi lebih akurat dalam merepresentasikan performa dari model kita.
Sering terdapat trade off ketika kita ingin mengoptimalkan salah satu dari metrics tersebut. Misalnya, untuk mendapatkan recall 100 persen kita cukup prediksi semua data sebagai positif, tapi tentunya hal ini akan membuat precision nilainya hancur lebur.
Sayangnya belum ada film dengan judul Total Precision dengan bintang utama Steven Seagal
Begitu pula sebaliknya, untuk mendapatkan precision yang tinggi, kita bisa hanya memasukkan prediksi yang kita benar-benar yakin sebagai kelas positif, akibatnya ada banyak data yang diprediksi sebagai negatif sehingga recall-nya yang sekarang menjadi jelek. Di sinilah kita harus memilih, mana yang mau lebih diprioritaskan, precision atau recall.
Beberapa problem lebih membutuhkan nilai precision yang tinggi. Misalkan untuk diagnosis penyakit, karena rumah sakit memiliki resource yang terbatas, lebih baik kita hanya memasukkan orang yang kita benar-benar yakin mengidap suatu penyakit (high precision), karena kalaupun kita salah diagnosis, orang tersebut bisa mencari rumah sakit lain.
Sedangkan untuk fraud detection, lebih baik recall-nya tinggi (banyak aktivitas fraud yang terdeteksi) walaupun akibatnya banyak transaksi valid yang kita mark sebagai fraud. Alasannya adalah legitimate user yang kita mark sebagai fraud tetap bisa melakukan validasi transaksinya, misalkan dengan memasukkan kode yg dikirim ke hape-nya oleh sistem 3-D secure visa (walaupun mungkin ini bisa menyebabkan friction tambahan ke customer sehingga conversion rate berkurang).
Kedua nilai ini bisa digabung lagi menjadi ke satu angka, misalkan untuk melakukan komparasi antar model yang berbeda. Salah satu cara untuk menggabungkannya adalah F1 score, alias harmonic means dari precision dan recall. Rumusnya kira-kira seperti berikut 2*precision*recall / (precision+recall).
Tapi kemudian timbul pertanyaan lain, karena sebenarnya nilai precision dan/atau recall ini bisa berbeda2 tergantung dari berapa threshold yang dipakai oleh classifier kita. Misalkan dengan threshold 0.5 kita mendapat 0.7 precision untuk 0.3 recall. Ternyata dengan mengurangi threshold menjadi 0.4, recall-nya naik menjadi 0.6 (2 kali lipat), sedangkan precision-nya hanya turun menjadi 0.66. Tentunya kalau dilihat secara singkat threshold kedua in general lebih baik dibanding yang pertama. Bagaimana kita bisa tahu threshold mana yang lebih baik untuk model kita?
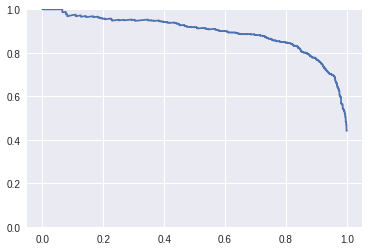
Untuk mendapat gambaran lengkap dari performa model kita di semua level threshold, kita bisa menggunakan Precision-Recall curve (PR curve). Kalau di sklearn, kita cukup masukkan hasil prediksi model kita yang dalam berupa score prediction (misalkan output dari method predict_proba) dan target labelnya ke dalam fungsi sklearn.metrics.precision_recall_curve.
Sumbu x adalah recall, dan sumbu y adalah precision. Dari gambar kurva di atas, kita bisa dengan cepat mengambil kesimpulan. Ketika nilai recall-nya rendah sekali (< 0.1) nilai precision bisa sangat tinggi, hampir 1. Sedangkan ketika nilai recall-nya tinggi sekali (> 0.99), nilai precision-nya menjadi rendah sekali, hampir 0.4. Tapi lihat, ketika nilainya recall-nya sekitar 0.8, kita bisa mendapat nilai precision yang juga cukup tinggi, sekitar 0.8. Sepertinya kompromi yang baik untuk kedua nilai tersebut.
Nah, bagaimana kalau kita ingin membandingkan antar 2 model mana yang lebih baik dengan menggunakan PR curve? Cara yang biasa dilakukan adalah dengan menghitung luas area di bawah kurva. Angka inilah yang disebut sebagai average precision.
Kalau di ranah information retrieval atau ranking, average precision ini nilainya dirata-ratakan lagi sejumlah query yang dites. Maka dia akan berubah menjadi mean average precision (MAP). Angka inilah yang kemudian akan dibandingkan untuk mendapatkan algoritma dengan performa yang terbaik. (Khusus untuk problem ranking, ini cuma dilakukan kalau misalnya labelnya hanya positif dan negatif. sedangkan jika labelnya adalah urutan yang sebenarnya, maka biasanya metrics lain seperti normalized discounted cumulative gain (NDCG) yang digunakan)
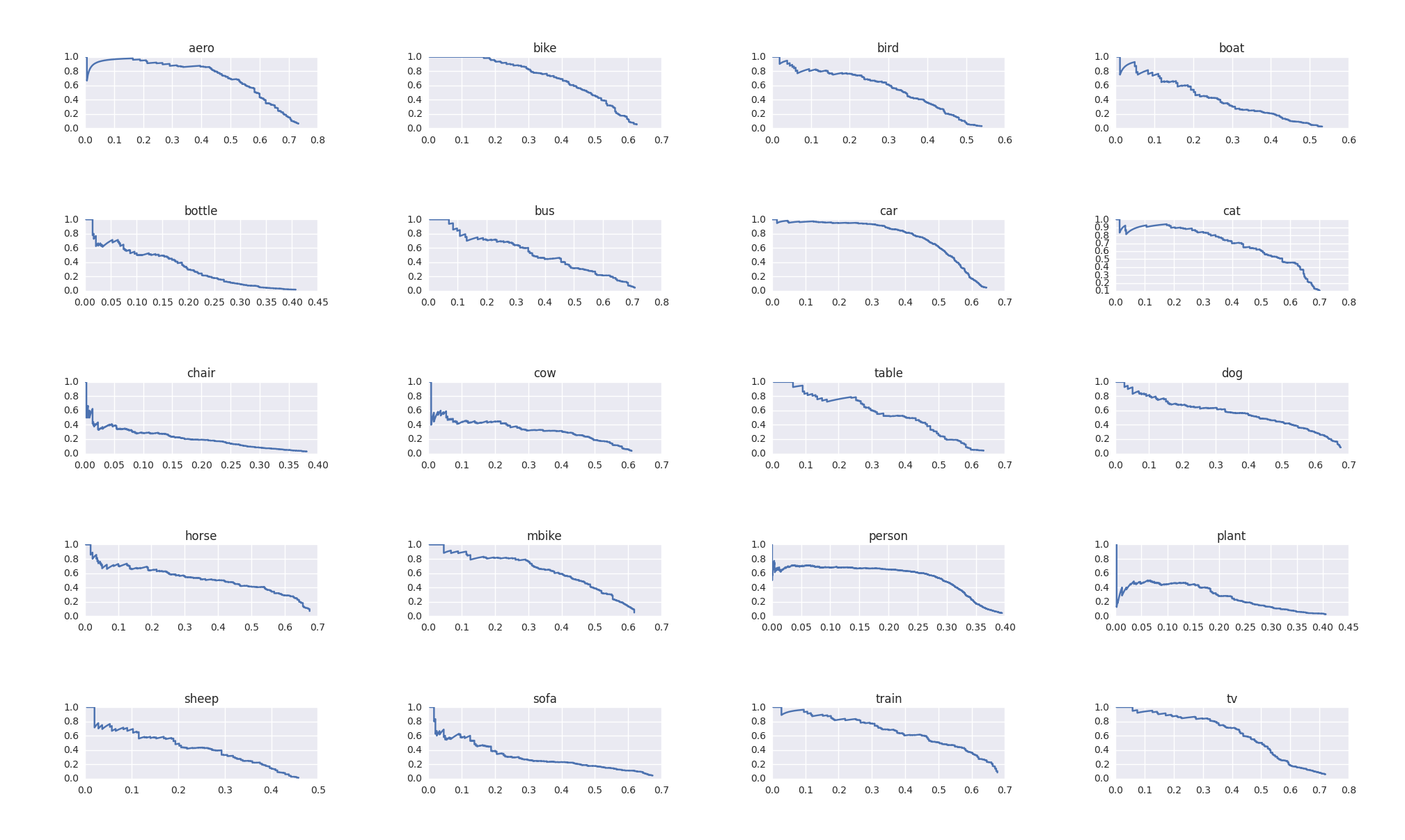
Kalau kalian memiliki lebih dari satu class (multi-class classification), average precision bisa dihitung dengan menggunakan binary classifier untuk setiap kelasnya. Kemudian nilai dari setiap kelasnya dirata-rata sehingga mendapat angka MAP-nya.
Contoh PR curve dari semua kelas untuk problem object detection.
Kira-kira demikian yang bisa saya share, semoga berguna di dunia nyata. Salam.
Alkisah, di dunia matematika terdapatlah sebuah bentuk geometrik abstrak yang pergi mengembara untuk menemukan potongan dirinya yang hilang, agar bisa melengkapinya hingga menjadi utuh kembali.
Pergilah ia menggembara menelusuri dunia Euclidean 2 dimensi yang luas tak terbatas. Di sepanjang perjalanannya tersebut, ia bertemu dengan banyak bentuk geometri lainnya yang memiliki berbagai macam rupa. Namun sayangnya tidak ada yang benar-benar cocok dengannya.
Lama ia mengembara, namun tak jua bertemu apa yang dicarinya. Ia pun termenung lama, memikirkan mengapa hal ini terjadi pada dirinya.
Ia pun akhirnya tersadar bahwa kalau hanya mencari yang cocok saja, maka dia bisa jadi tidak akan pernah menemukan yang cocok karena peluangnya yang sangat-sangat kecil. Yang harus dia lakukan adalah ikut berubah, mengikuti bentuk yang lain, agar bisa sama-sama cocok.
Akhir cerita, ia pun menemukan bentuk lain, yang berkat usaha dan kerja keras dari kedua belah pihak, mereka menjadi cocok, dan hidup bahagia selamanya.
Pada post kali ini saya ingin menjelaskan sedikit teknik-teknik yang biasa dipakai untuk menghadapi dataset yg imbalanced untuk kasus supervised learning, dimana jumlah data dari suatu kelas jauh lebih sedikit dibanding kelas lainnya. Hal ini sering kali muncul di dunia nyata, seperti fraud detection (malah ngeri kalau misalkan jumlah kasus fraud-nya ada banyak, bisa gulung tikar bisnisnya) atau deteksi penyakit langka (cuma 1 dari 1 juta orang yang menderita). Tidak mungkin kita berdoa agar lebih banyak orang menderita sakit biar data training kita bertambah, kan?
1. Biarin aja
Ya, dibiarin aja. Abaikan dan lakukan training seperti biasa. Karena siapa tahu memang kedua kelas tersebut berbeda jauh dan sudah linearly separable. Asal jangan lupa untuk menggunakan metrics yang tepat (bukan akurasi), seperti precision/recall.
2. Downsampling kelas mayoritas
Biar fair ketika dilakukan perhitungan error, jumlah kelas mayoritasnya dikurangi.
3. Upsampling kelas minoritas
Atau sebaliknya, jumlah kelas minoritasnyalah yang ditambah. Upsampling bisa dilakukan dengan cara mengambil data yang sama berulang-ulang (sampling with replacement) atau dengan generate data baru dengan menggunakan algoritma semacam SMOTE.
4. Pakai weighted loss
Atau kita bisa langsung modifikasi loss function-nya agar kelas minoritas mendapat bobot yang lebih tinggi kalau diprediksi salah oleh modelnya. Seberapa besar bobotnya? Paling gampang diset menjadi inversely proportional dengan jumlah data sekarang yang ada. Jadi kalau misalkan perbandingannya 1:2, maka bisa diset minimal bobot kelas positif 2 kali kelas negatif.
Weighted loss ini sendiri bisa dilihat sebagai cara menggunakan sampling secara implisit.
Penutup
Kira2 itu sedikit cara2 untuk meng-handle imbalanced data pada problem classification yang straightforward. Pendekatan yang lebih ekstrem adalah dengan menformulasikan ulang permasalahannya menjadi ranking problem atau novelty/outlier detection. Tapi ini mungkin bahasan di lain hari.
awas salah ngasih tahu abang gojeknya belok kiri atau kanan
Pembukaan
Pernahkah Anda berada dalam keadaan harus memilih di antara 2 pilihan, di mana pilihan yang Anda ambil itu dapat mengubah kehidupan Anda secara drastis?
Saya pernah dan hampir mengalaminya setiap hari. Setiap pulang dari kantor saya selalu dihadapkan pilihan untuk naik bis atau naik busway. Skenario pertama adalah saya langsung dapat bus dan sampai rumah dengan cepat. Skenario kedua saya langsung dapat busway, sampai rumah lumayan cepat tapi lebih capek karena harus berdiri. Skenario terburuk adalah menunggu bus, bus tidak lewat dalam waktu satu jam, Kemudian jadinya menunggu busway, tapi kemudian bisnya malah lewat di depan mata, akhirnya baru dapat busway 30 menit kemudian, itu pun berdiri hingga 1.5 jam karena jalan macet…
Efeknya tentunya sangat berpengaruh. Kalau saya dapat opsi yang pertama, maka saya bisa sampai rumah dengan waktu yang relatif lebih cepat, badan tidak terlalu capek, dan mungkin malamnya bisa produktif sedikit seperti untuk menulis blog atau belajar hal baru dengan menonton video online course.
Bandingkan dengan opsi terakhir yang mana saya sampai rumah larut malam dan kehabisan tenaga sehingga saya hanya bisa menghabiskan waktu dengan menonton video pewdiepie di youtube atau main hearthstone tanpa mikir.
Bandit algorithm
Joking aside, contoh kisah nyata di atas hanyalah ilustrasi belaka untuk menggambarkan suatu kelas masalah yang di matematika dikenal dengan nama bandit algorithm. Bandit algorithm ini namanya terinspirasi dari mesin slot yang ada di kasino2.
hati-hati judi dapat meracuni kehidupan, kata bang roma
Penjelasan resminya dari algoritma bandit kira-kira seperti berikut. Pada setiap turn kita memiliki beberapa opsi yang bisa dipilih. Masing-masing opsi akan memberikan reward/hadiah dengan jumlah yang kita belum ketahui sebelumnya. Tugas kita adalah memaksimalkan total reward yang kita dapatkan dari awal pilihan pertama hingga pilihan terakhir. Terdengarnya susah-susah gampang bukan?
Ada juga yang mengklasifikasikan algoritma bandit ini ke dalam special case dari reinforcement learning (RL yang tidak memiliki states). Kalau penasaran, lebih lanjutnya bisa cek chapter 1 dari buku Reinforcement Learning-nya Sutton & Barto.
Implementasi
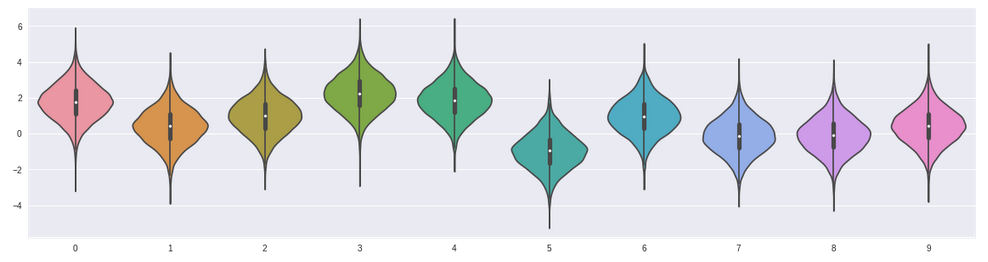
Untuk mengetes performa dari algoritma2 yang akan kita coba, pertama kita generate terlebih dahulu 2000 simulasi yang masing-masing memiliki distribusi reward yang berbeda-beda. Simulasi ini akan kita jalankan selama 1000 putaran. Contoh salah satu distribusinya adalah sebagai berikut:
option 3 dan 4 punya reward yg relatif lebih besar dari pilihan lainnya, tapi kita tidak tahu informasi itu di awal
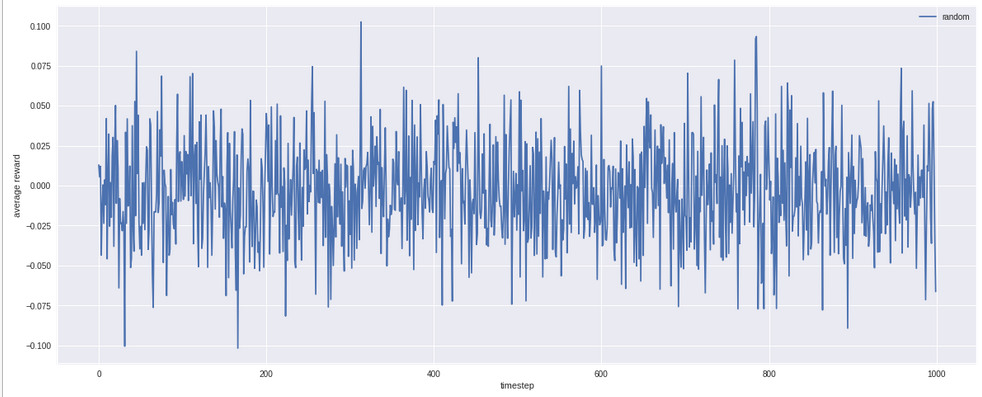
Apa strategi pertama yang bisa kita coba? Pure random. Di tiap turn kita pilih saja opsi terserah yang mana saja. Kalau misalkan random saja sudah bagus, ngapain mikirin algoritma lain yang lebih rumit?
Ternyata kalau random, rata2 reward yg kita dapat untuk masing-masing putaran berkisar di angka 0. Weks, jelek sekali performanya.
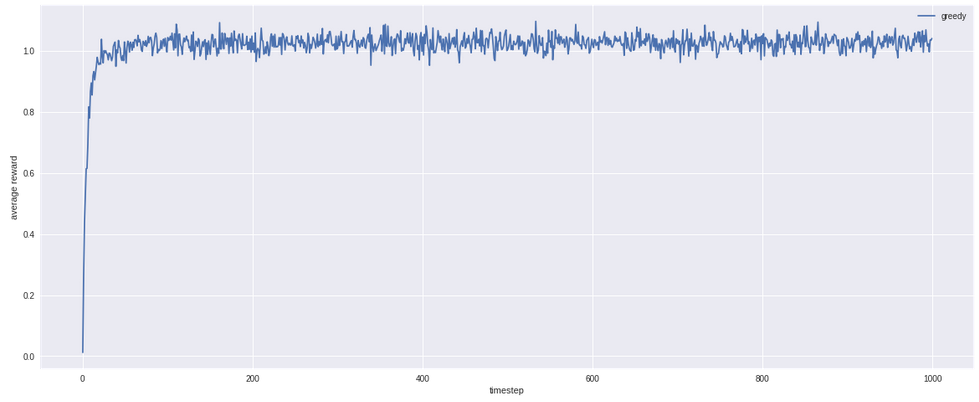
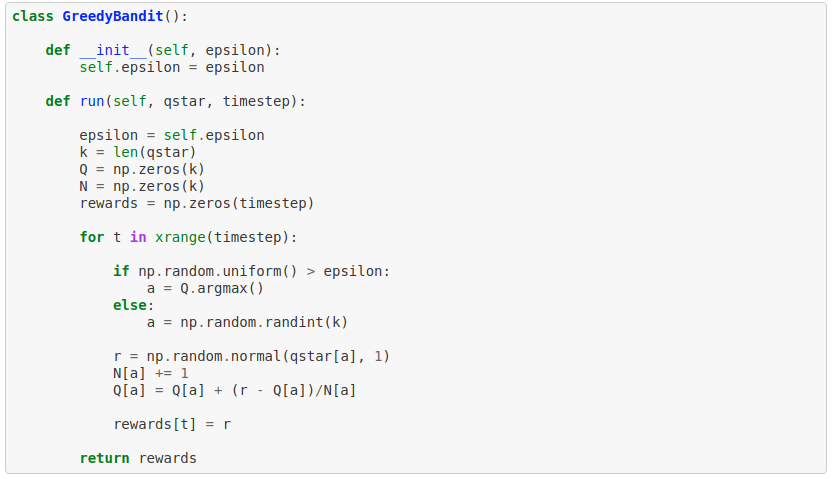
Bagaimana kalau kita bersifat serakah (greedy), jadi kita hanya memilih opsi yang selama ini memberikan rata2 reward paling tinggi?
Lumayan, hasilnya secara rata-rata lebih bagus dari random (1, bukan 0). Kekurangannya adalah, karena sifatnya yang greedy, begitu kita memilih opsi yang memberikan nilai positif, maka kita bakal terus-terusan memilih opsi tersebut. Padahal di luar sana mungkin ada pilihan yg bisa menghasilkan reward yang lebih tinggi.
Untuk mengatasi hal tersebut, kita harus bisa menyeimbangkan antara exploitation (mengumpulkan reward sebanyak-banyaknya dengan memilih opsi yang pasti memberikan hasil bagus) dengan exploration (mencari opsi yang mungkin memberikan hasil yang lebih bagus lagi). Salah satu strategi yang bisa dipakai adalah e(epsilon)-greedy. Jadi pada setiap turn, kita punya peluang sebesar e untuk memilih opsi lain secara random. Nilai e ini sendiri jelas harus dipilih secara bijak, karena kalau terlalu kecil maka kita bisa terjebak di pilihan yang tidak optimal, tapi kalau terlalu besar maka kita akan melewatkan terlalu banyak kesempatan untuk mendapat reward yang pasti besar, sehingga secara kumulatif total reward yang kita kumpulkan bisa lebih kecil.
Implementasi-nya kira-kira seperti berikut:
Wow, sekarang kita bisa mendapatkan nilai dari 1.2 hingga 1.4, tergantung nilai e yg kita pilih.
Now can we do even better than that? Tentu saja. Perhatikan, pada strategy e-greedy, pada saat kita melakukan eksplorasi, kita memilih opsi secara random, tidak peduli terhadap performanya yang sebelumnya. Bagaimana kalau misalkan kita pilih suatu opsi berdasarkan rata-rata performanya sekarang dan yang paling sedikit dipilih sejak saat ini. Motivasinya adalah opsi yang jarang dipilih bisa jadi memiliki potensi memberikan reward besar yang belum terealisasikan.
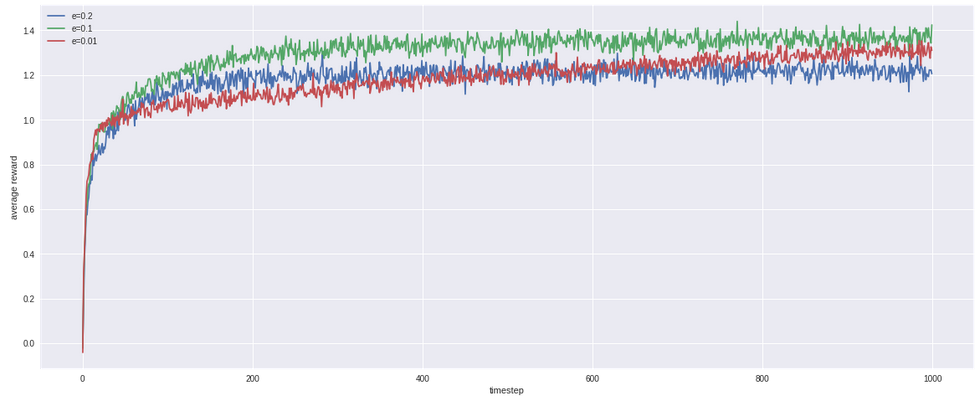
Strategi ini bernama Upper Confidence Bound (UCB). Untuk derivasi lengkapnya, bisa diintip di blog-nya bang Jeremy Kun. Implementasinya kira-kira seperti ini:
Dan hasilnya ternyata memang paling bagus di antara algoritma-algoritma sebelumnya, hingga 1.5!.
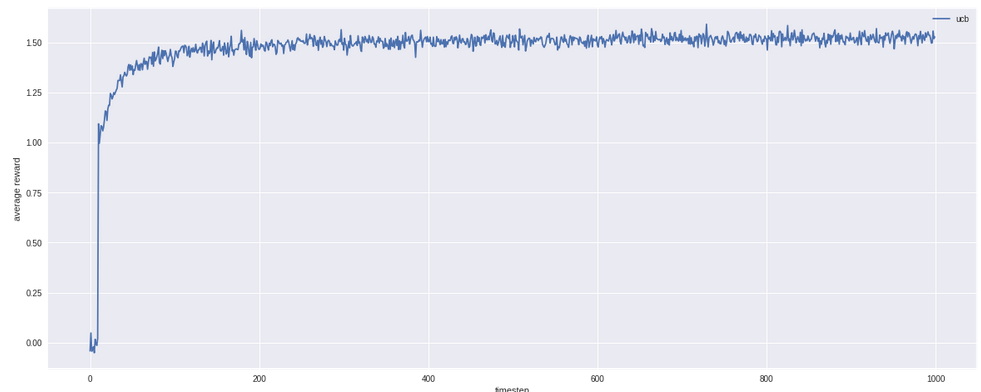
Dan ini adalah perbandingan semua algoritma yang sudah disebut di atas. UCB memiliki nilai paling tinggi dan paling cepat juga mencapai nilai tersebut.
Penutup
Apa aplikasi langsung yang bisa dicoba dengan menggunakan teknik ini? Misalkan kamu mau mengoptimisasi conversion rate dari sebuah website dengan mencoba beberapa versi dari landing page-nya. Conventional wisdom-nya adalah kita lakukan A/B test untuk mengetahui varian mana yang performanya paling bagus. Nah, tapi seringkali A/B test ini harus dilakukan dalam jangka waktu yang lumayan lama dengan agar jumlah sampelnya cukup secara statistik. Dengan menjalankan A/B test ini, kita kehilangan potensi untuk menghasilkan reward karena sebagian user akan mendapat varian yang mungkin secara performa lebih buruk daripada yang lainnya.
Nah, kalau misalkan kita formulasikan ini sebagai problem bandit dengan menggunakan algoritma UCB misalnya, maka sistem akan secara otomatis meng-assign user ke varian yang mempunyai performa yang paling bagus. Tanpa harus menunggu A/B test-nya selesai sehingga total cumulative reward yang dikumpulkan di akhir jauh lebih tinggi.
Lalu apakah dengan adanya bandit algorithm maka A/B testing jadi obsolete? Tentu saja tidak, karena keduanya memiliki tujuan yang berbeda. Berikut wejangan dari om Chris Stucchio.